This post describes my setup on building Anki repetition-learning decks for complicated words I need to translate when reading German websites. This should work for most languages.
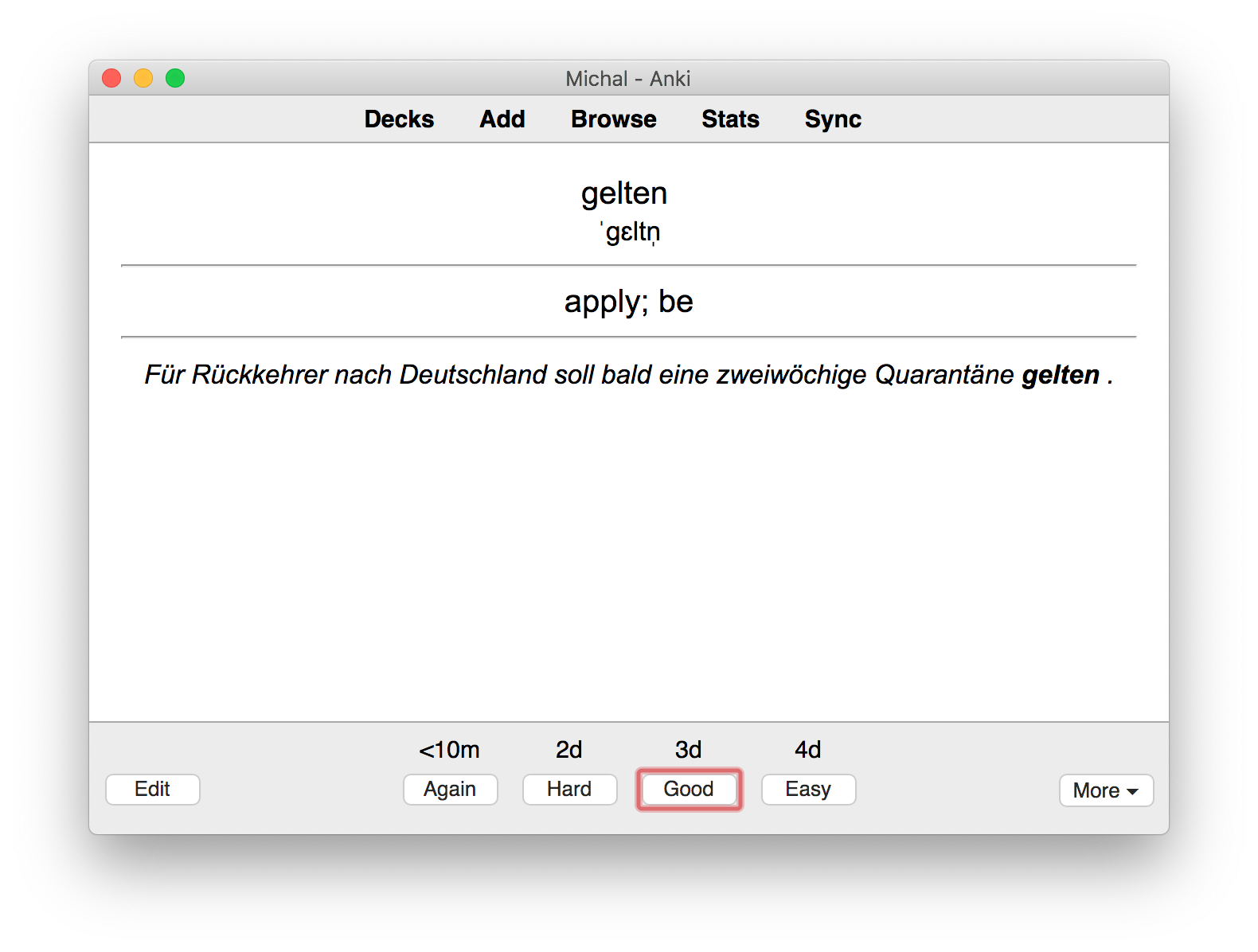
The end product in a MacOS Anki learning mode
FluentCards
FluentCards is Chrome extension that creates a pop-up with the translated word (using Yandex dict) in the context of the web page. It’s like Google Translate, but contains one, super-useful feature: it allows you to store the word, the translation, and the context for the word for later.
This is done by visiting Fluentcards Vocab page, which after a short while (I think it uploads these hourly), will list all the words you’ve looked up. Moreover, it allows you to download the words in Anki Basic, Anki Cloze and Memrise formats.
I usually study with Anki two-side cards (🇩🇪>🇬🇧 and 🇬🇧>🇩🇪). Unfortunately the fluentcards formatting of the Anki Basic combines the translated word, with IPA and context in a single field. This means that if you re-add the word, you’ll end up with duplicates in Anki.
Moving to a better format
I wrote a simple Python script that takes the word IPA context HTML of fluentcards format, and outputs a well-formatted, 4-field (word, translation, IPA, context) TSV file for inport into Anki.
To run it, make sure to have Python 3 installed, and follow the --help instructions.
#!/usr/bin/env python3
"""Converts fluentcard.com "Anki Basic" TSV HTML file to a four field TSV."""
from xml.dom import minidom
import argparse
import os
def fluent_line_to_dict(line):
"""Parses a Fluentcard.com TSV line into 4 fields"""
# <big class="word">genug</big><br /><small class="ipa">ɡəˈnuːk</small><p class="context">Um effektiv Vokabeln zu trainieren, ist eine Wiederholung nicht <b>genug</b>.</p> enough
out = {}
html_like, out['translation'] = line.split("\t")
# A little hack, allowing minidom to parse it by having a single html top level document node.
dom = minidom.parseString("<html>" + html_like + "</html>")
def _html_content_for_tag(tag):
try:
return ' '.join([n.toxml() for n in dom.getElementsByTagName(tag)[0].childNodes])
except IndexError:
return ' ' # in case we didn't find that tag
out['word'] = _html_content_for_tag('big')
out['ipa'] = _html_content_for_tag('small')
out['context'] = _html_content_for_tag('p')
return out
def main():
parser = argparse.ArgumentParser(description="Convert fluentcard.com Anki Basic TSV with HTML into a four field TSV")
parser.add_argument('input_file', metavar='input', type=str,
help='input file to process')
parser.add_argument('--output', metavar='output', dest='output_file', type=str, default=None,
help='output file (defaults to <input>.4f.tsv)')
args = parser.parse_args()
if not args.output_file:
args.output_file = os.path.splitext(args.input_file)[0] + '.4f.tsv'
in_lines = []
try:
with open(args.input_file, 'r') as in_file:
in_lines = [l.rstrip() for l in in_file]
except IOError as e:
print('Could not read file "{}": {}'.format(args.input_file, e))
out_lines = []
for line in in_lines:
out_lines.append("{word}\t{translation}\t{ipa}\t{context}".format(**fluent_line_to_dict(line)))
try:
with open(args.output_file, 'w') as out_file:
out_file.writelines([l + "\n" for l in out_lines])
except IOError as e:
print('Could not write file "{}" file: {}'.format(args.output_file, e))
if __name__ == "__main__":
main()
Just copy paste it to a terminal and make it executable
cat > ~/fluent_4f.py # copy paste here, once done press Ctrl+D
chmod +x ~/fluent_4f.py
Run the script of the newly downloaded Anki Basic .tsv file like so:
~/fluent_4f.py ~/Downloads/German_basic_18_04_2020.tsv
Adding a new note type to Anki
The whole reason why we’re converting the files, is to make Anki understand the IPA and context as separate fields. In order to do that, we need to add a new note type with four fields. We will also add two card that will utilize these fields.
Step 0: Get Anki
First, you have to have Anki installed (downloads page). Moreover, I highly recommend setting up an AnkiWeb account, which will allow you to synchronize the state of your decks across devices.
Step 1: Add a new deck
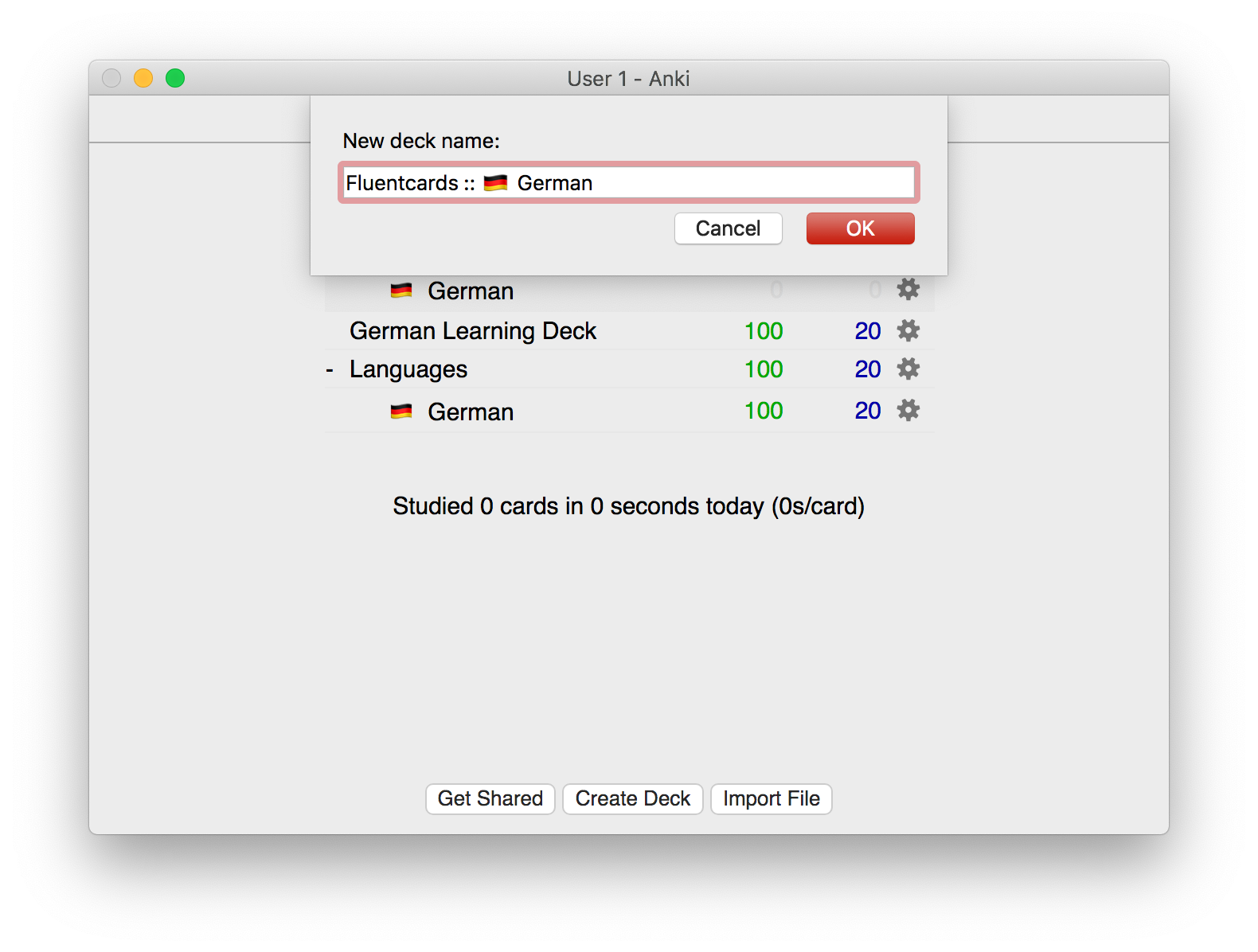
Create a deck, hint: :: acts as nesting.
Step 2: Create a new note type
Before you do this, plase note that adding new note types and card types makes differential syncing impossible. This means that one of your devices will wriite its full state to AnkiWeb. As such, it is a good idea to hit Sync on all your devices before proceeding.
You can read more on this in Anki docs on note creation.
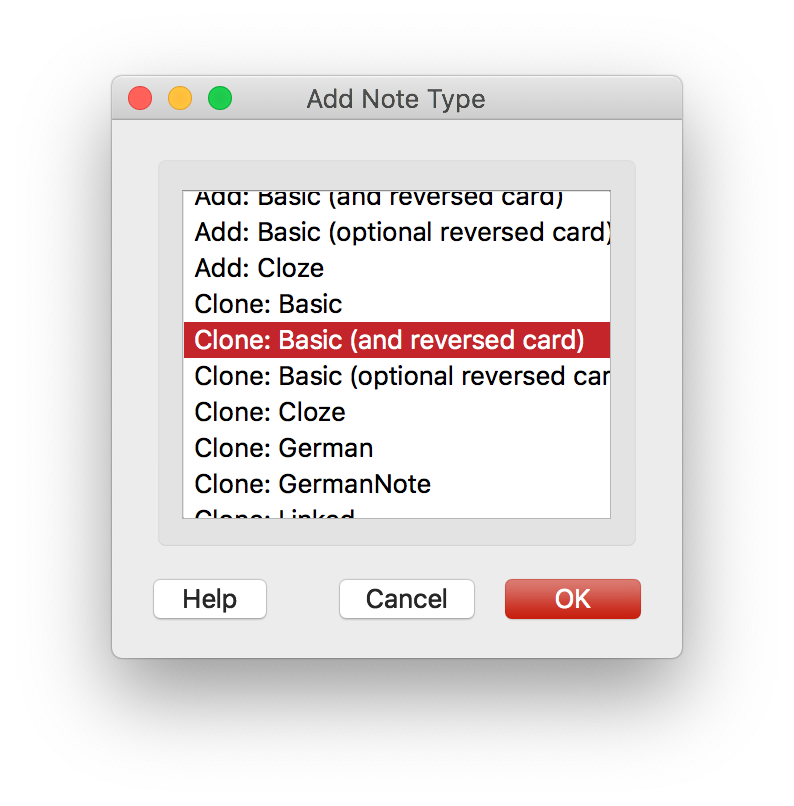
You can clone an existing Basic with Reverse note
Step 3: Add revelant fields
The extra fields we will introduce are IPA (pronounciation) and context (the sentance that Fluentcards extracted it from). It is importatnt to have them in the same order, so the auto-import feature doesn’t require you to manually adjust fields.
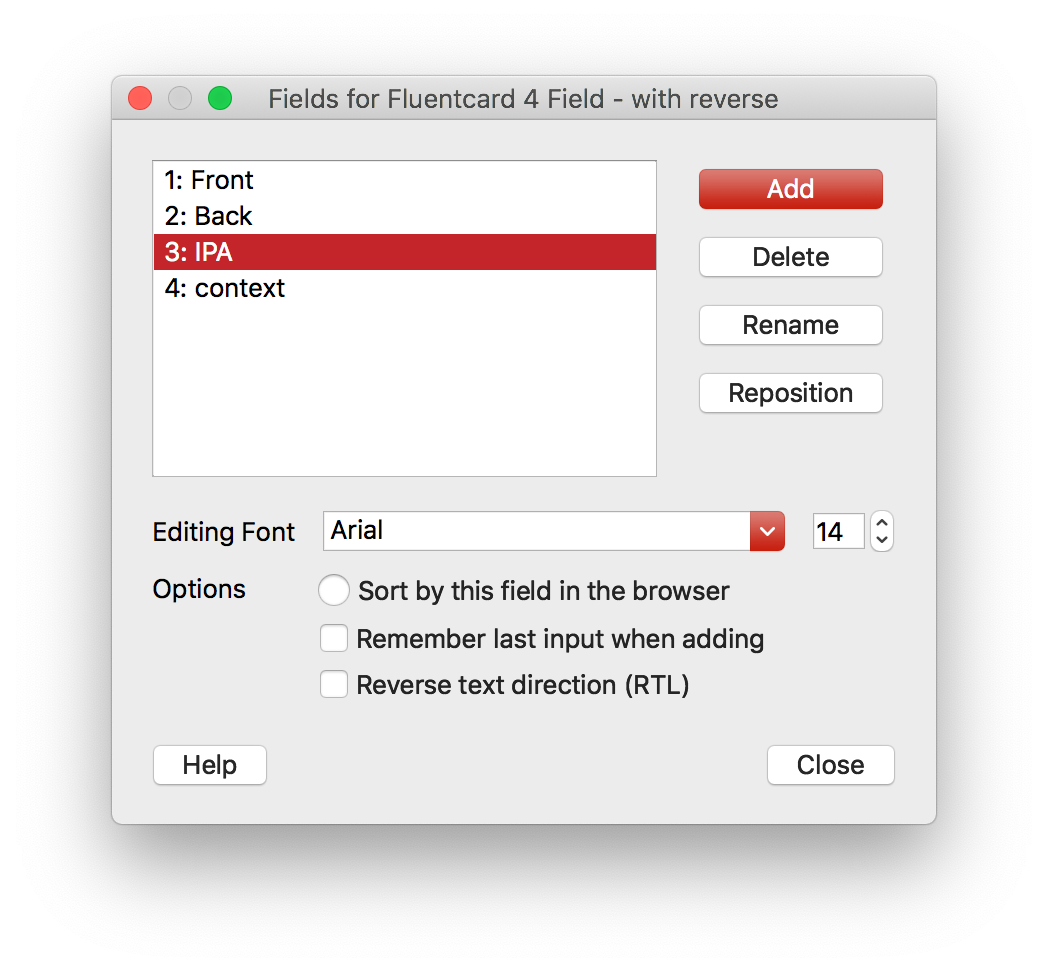
You can clone an existing Basic with Reverse note
Step 4: Edit card type
In this step we will add custom card types (templates for what is presented) for Front>Back (🇩🇪>🇬🇧) and Back>Front ( 🇬🇧>🇩🇪) learning. It’s quite a simple modification to the Basic (with reverrse) note we copied from. If in doubt, consult documentation.
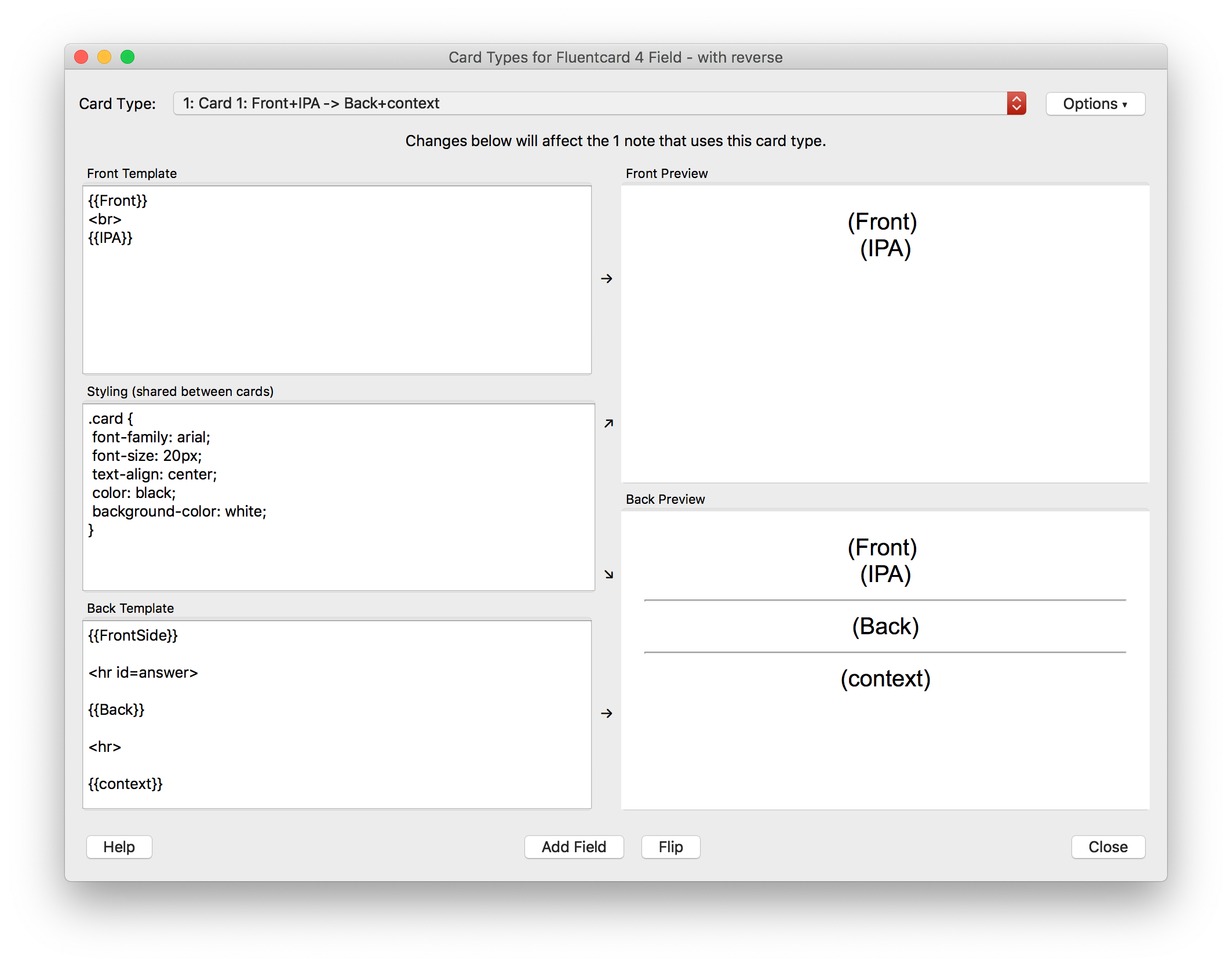
Step 5: Import
Before you import anything, it may be worthwhile hitting Sync, so your new note and card types get uploaded to AnkiWeb.
At this point you should take your 4f.tsv file that the fluent_4f.py script spit out (into the same directory the original file was in), and use Import to add it to your new deck from Step 1.
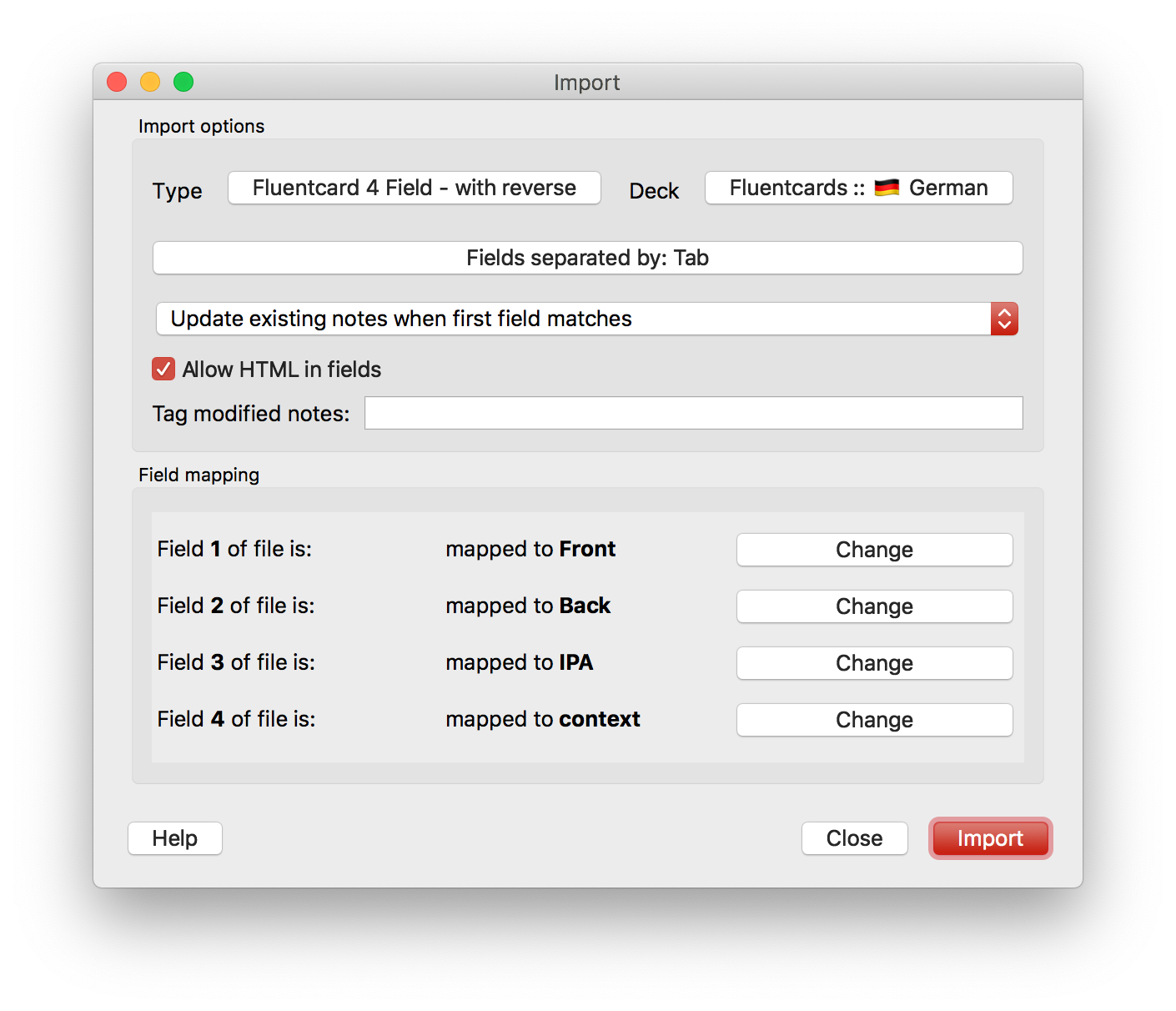
Note that all fields are in the right order
Step 6: Play around and update
This should be it. Your cards are ready for learning. If you press Sync, they’ll be available in AnkiWeb via a browser, iOS and Android clients.
The context sentance is super useful
Since the note is keyed on the Yandex dictionary output in German, any subsequent re-imports of the whole Fluentcards dump (processed via fleuent_4f.py) will not overwrite, but only update your deck with new cards.
Enjoy ☺️